import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import gensim
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer,TfidfTransformer
import sklearn.feature_extraction.text as text
from sklearn.linear_model import LogisticRegression
from sklearn import decomposition
from IPython.display import Image
from IPython.display import HTML
from IPython.core import display
%matplotlib inline
from pylab import rcParams
rcParams['figure.figsize'] = 15, 10
plt.style.use('fivethirtyeight')
# This line will hide code by default when the notebook is exported as HTML
display.display_html('''<script>jQuery(function() {if (jQuery("body.notebook_app").length == 0)
{ jQuery(".input_area").toggle(); jQuery(".prompt").toggle();}});</script>''', raw=True)
def output_columns(df,rounding=2):
'''
Changes columns name from "python_naming" to "Output Names"
'''
#keep as a dataframe to perform vectorized string operations
names = pd.DataFrame(df.columns)
names.columns= ['temp']
names = pd.DataFrame(names.temp.str.replace("_", " "))
df.columns = list(names.temp.str.title().str.replace('usv','USV',case=False))
return df
posts = pd.read_csv('data/usv_posts_cleaned.csv',encoding='utf8',parse_dates=True)
posters = pd.read_csv("data/usv_posters_cleaned.csv",encoding="utf8")
posts.date_created = pd.to_datetime(posts.date_created)
posters['relation_to_USV'] = np.where((posters.ever_usver)&(posters.is_usver==False),'Former USVer','Civilian')
posters.ix[posters.is_usver,'relation_to_USV'] = "Current USVer"
What is this?¶
This is an analysis of USV.com post data from inception to Feb 2015. For a few years, USV.com was my favorite place to hang out on the internet. There was once a section on the website called "Conversation". It looked like this:
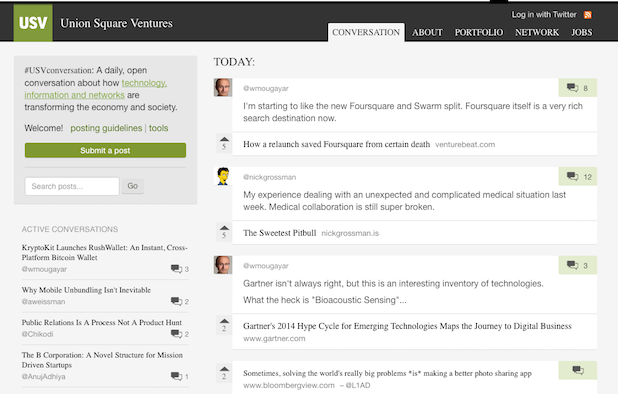 Any user could submit links to an article. The community would comment and upvote them. The links were ranked by comments, upvotes and time submitted. This started as a Hack Day project to understand who was contributing value to the community and topics the community liked to discuss.
Any user could submit links to an article. The community would comment and upvote them. The links were ranked by comments, upvotes and time submitted. This started as a Hack Day project to understand who was contributing value to the community and topics the community liked to discuss.
There are three sections:
Poster segments: Identify poster segments, who is in them and how they compare against each other.
Post Patterns: Words and topics that are popular with the community, Trends in posting time.
Poster Profiles Words and topics that specific posters prefer.
The data set of posts includes:
- the poster's twitter handle
- the post title
- the user submitted description (body text)
- the time of the post
- who upvoted it
- comments and upvotes received
This is all publicly scrapable, but was given to me during a Hack Day.
Below is an example of the post data set, sorted by comment count:
output_columns(posts.sort_values('comment_count',ascending=False)).head()
poster_metrics = ['poster','post_count','mean_comments','conversations_sparked',
"percent_of_posts_with_comments",'relation_to_USV']
output_columns(posters.sort_values('conversations_sparked',ascending=False)[poster_metrics].head(10).round(2))
All of the data on posters is calculated from the posts's above. I also manually added whether or not the post works at USV or worked at USV as of Feb 2015, which is when I did this. The only difference is that Brittany worked at USV in Feb 2015 and now works at Lattice.vc in May 2016.
# Highest ranked non-USVer posters
output_columns(posters.loc[(posters.ever_usver==False)&
(posters.conversations_sparked>1)].sort_values('conversations_sparked')).to_csv('Top Posters.csv',index=False)
Current and Former USVers¶
Here are the stats for all current USVers and alumni:
output_columns(posters.ix[posters.ever_usver,poster_metrics].sort_values(['relation_to_USV','post_count']))
# Create a csv of all USVers
output_columns(posters.loc[posters.ever_usver==True].sort_values('conversations_sparked',ascending=False)).to_csv("USVers by the Numbers.csv",index=False)
Infrequent, but High Value Posters¶
This is a segment of posters that post infrequently, but have high per post engagment. This is a group that the community wants to hear more from. The cutoffs are:
- Averages more than 2 comments per post
- Posted between 5 and 15 times
These cutoffs, like all cutoffs, are somewhat arbitrary. They felt directionally correct to me.
output_columns(posters.ix[(posters.mean_comments>2)&
(posters.post_count>=5)&
(posters.post_count<=15),poster_metrics].sort_values('mean_comments'))
# Uncoment and move up to output as a CSV
# .to_csv('Occasional, but Valuable Posters.csv',index=False)
posts = posts.merge(posters[['poster','is_usver','ever_usver']],on='poster',how='left')
USVers vs Civilians¶
This is the average number of conversations sparked by posters based on their relationship to USV:
sns.barplot('relation_to_USV','conversations_sparked',data=posters, palette="Blues_d",estimator=np.mean,ci=None)
sns.plt.title("Current and Former USVers vs Civilians")
sns.axlabel("Relationship to USV","Average Conversations Sparked")
plt.ylim(0,35)
sns.plt.savefig("USVers vs Non-USVers (Top Posts).png", dpi=100)

Current USVers tend to spark more conversations. Could that be because the civilian category is weighed down by inactive accounts?
Here is amount of current USVers, former USVers and Civilains who have posted.
posters.groupby('relation_to_USV').count()[['poster']].rename(columns={'poster':'Number of Unique Posters'})
There are a lot more Civialians. Perhaps, it's not surpising that their average was low. Below is the same plot, except it gets the maxium conversations sparked, instead of the average for each group.
sns.barplot('relation_to_USV','conversations_sparked',data=posters, palette="Blues_d",estimator=np.max,ci=None)
sns.plt.title("Current and Former USVers vs Civilians")
sns.axlabel("Has Worked For USV","Max Conversations Sparked in Each Group")
plt.ylim(0,35)
sns.plt.savefig("USVers vs Non-USVers (Top Posts).png", dpi=100)

As you can see, some Civilians (or at least one) have sparked a comparable number of discussions to the USVers. The average USVers does spark more conversations than the average civilian. However, the most active civilians are comparable to USVers.
Post Patterns¶
Post Enagagement by Time Posted¶
Does it matter what time of day a post is made?
posts.groupby(posts.date_created.dt.hour).mean()[['upvotes','comment_count']].plot(legend=True)
plt.ylim(0,5)
plt.title('USV.com -- Average Upvotes and Comments by Hour of the Day')
plt.xlabel('Hour of the Day')
plt.ylabel('Average Count')

There is not a strong pattern between when something is posted and the number of upvotes and comments it recieves.
This is what the same graph looks like for Product Hunt (data pulled from their API):
Image(filename='images/Counts-and-Upvotes-by-Hour-Product-Hunt.png')

Product Hunt has s strong pattern based on time of day. This is because Product Hunt resets every day. USV.com does not.
This could indicate an opportunity. If USV.com built in a predictable time cycle for new posts, it could lead to habitual visits, posts and discussions. Reddit and Hacker News show you don't need a daily leaderboard that restart at midnight. However, people should expect to see new content at some time interval. AVC does this very well.
##
# posts.set_index('date_created')['comment_count'].resample('M').count()[:-1].plot()
# That is the evolution of montly posts over time. USV.com was primarly a blog for occasional
# posts from 2006 - 2013. You can see when USV.com allowed anyone to submit links. By number of
# posts, this peaked in 2013. However, I think number of posts is the wrong metric.
Posts The Community Likes To Discuss¶
First, we must define "likes to discuss". One way to define it is by number of comments. Here is the distribution of posts by the number of comments recieved:
posts.comment_count.loc[posts.comment_count>=0].hist(bins=250)
plt.xlabel('Number of Comments')
plt.ylabel('Number of Posts')
plt.title('Distribution of Comments')
plt.savefig('Distribution of Comments.png')
plt.xlim(0,50)
print "Comment Count Skew: " + str(posts.comment_count.skew().round(2))

As can be seen above, most posts get 0 or very few comments. The skew is very postive (23+). Let's define a popular post as one that sparks a discussion by getting at least 5 comments.
# posts.comment_count.value_counts(normalize=True).round(4).sort_index()*100
# That is the distribution of comments. As you can see, 73% of posts got no comments. 90% got 3 or fewer comments.
top5_cutoff = posts.comment_count.quantile(.95)
# print "The top 5%% of posts got at least %s comments so that will be the cutoff." %int(top5_cutoff)
posts['sparked_conversation'] = posts.comment_count>top5_cutoff
posts['got_comments'] = posts.comment_count>0
posts[['title','body_text']] = posts[['title','body_text']].fillna('')
Optional Explanation of Math
Now, I will use the TF-IDF* weighting of one and two word phrases that appear in at least 20 posts titles. TF-IDF, is just the word counts in each title relative to how rare the words are across all titles.
vec = CountVectorizer(ngram_range=(1,2),min_df=20,stop_words='english')
X_words = vec.fit_transform(posts.title)
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X_words)
Next, I fit a logistic regression model using l1 regularization. This uses the tfidf words to predict whether or not the post will spark a conversation. Logistic regression is not the most predictive model, but it is interpretable, which is the goal of this.
Note that data set is small (relative to the number of features), which makes it hard to do proper cross validation. Instead, I am using regularization and requiring that a phrase appears 20+ times to reduce overfitting. Even so, I wouldn't try to make predictions with this model.
y = posts.sparked_conversation
model = LogisticRegression(penalty='l2')
model.fit(tfidf,y)
print
vocab = zip(vec.get_feature_names(),
model.coef_[0])
df_vocab = pd.DataFrame(vocab)
Popular Title Words
The higher the coef, the more likely a word is to spark a conversation. Here are the top 20 words:
df_vocab.columns = ['word','coef']
df_vocab.sort_values('coef',ascending=False).head(20)
Topics on USV.com¶
Above we looked at the titles. Now, let's check out the post description. By using non-negative matrix factorization, I tried to pull out topics.
The post descriptions have too few words for perfectly reliable topic models. Many topics were sensitive to hyperparamters. Even with all of the noise, there were still some topics that stood out.
Below are some topics and their top 10 words. I did not use tags to find these. This came solely from which words appear together in descriptions.
posts['body_text_raw'] = posts.body_text
posts['body_text_clean'] = posts.body_text.str.replace(r'\[a-z][a-z][1-9]\[a-z][a-z][a-z]', '', case=False)
posts['body_text_clean'] = posts.body_text_clean.str.replace('\'', '', case=False)
posts['body_text_clean'] = posts.body_text_clean.str.replace('[a-z]/[a-z]', '', case=False)
custom_stopwords= ['looks','look','read','great','good','dont','really','done','kik','lets',
'http','let','just','that','thats','like','lot','interesting','think','im',
'thought','thoughts','id','love','twitter']
my_stop_words = text.ENGLISH_STOP_WORDS.union(custom_stopwords)
# This step performs the vectorization,
# tf-idf, stop word extraction, and normalization.
# It assumes docs is a Python list,
#with reviews as its elements.
cv = TfidfVectorizer(ngram_range=[1,1],max_df=0.6, min_df=4,stop_words=my_stop_words)
doc_term_matrix = cv.fit_transform(posts.body_text_clean)
# The tokens can be extracted as:
vocab = cv.get_feature_names()
#trial and error got me to 45
num_topics = 45
#doctopic is the W matrix
decomp = decomposition.NMF(n_components = num_topics, random_state=50,init = 'nndsvda')
doctopic = decomp.fit_transform(doc_term_matrix)
n_top_words = 10
topic_words = []
for topic in decomp.components_:
idx = np.argsort(topic)[::-1][0:n_top_words]
topic_words.append([vocab[i] for i in idx])
topic_names = [
"Web Services", "Bitcoin and Blockchain","AVC or Continuations","Customer Success",
"Mobile","USV Community","Startup Ecosystems","Data Privacy and Security",0,"Net Neutrality",1,"Long Read",2,
"Venture Capital",3,"Tech Job Market","HTML Tags","Internt Access",4,"Markets","Test Post",
"Big 4 Tech Co's","Linux & Cloud","Business Models","App Store",5,6,7,8,9,10,11,"iOS vs Android",12,
"AVC Posts",13,14,"Community Feedback","Technology and Patents","Video","Startup Building",15,
"Open Source","Product Development",16
]
#outputs all named topics and its top 10 words
for count,i in enumerate(topic_words):
if isinstance(topic_names[count],int):
pass
else:
print "Topic: %s"%topic_names[count]
print "Top words: " + ", ".join(i)
print
posts['clean_upvotes']= posts.voted_users.str.replace('^u|\'|\[|\]','')
users_votes = posts.clean_upvotes.str.get_dummies(",")
users_votes.columns = users_votes.columns.to_series().str.replace('^u','')
posts = pd.concat([posts,users_votes],axis=1)
model = LogisticRegression(penalty='l2')
y = posts.sparked_conversation
model.fit(doctopic,y)
print
This is how well a topic predicts if the community will discuss it. This is grossly simplifying. Topic popularity should changes over time. Different user segments probably have different preferences. Even so, it's quite interesting.
community_topics = pd.DataFrame([pd.Series(topic_names),model.coef_[0]]).T.sort_values(1,ascending=False)
community_topics.columns=["Topic","Coefficent"]
community_topics[community_topics.Topic.map(lambda x: type(x))!=float]
Finding Posts on a Topic¶
We can use these topic models to find posts on a topic. For example, "Bitcoin and Blockchain" is a clear topic. These are the "most Bitcoin" posts. These posts are sorted by how strongly it's description is associated the Bitcoin Topic. This could be used for a recommendation engine. However, not all topics came through as cleanly as Bitcoin.
doctopic_df = pd.DataFrame(doctopic)
doctopic_df.columns = topic_names
posts_topics = pd.concat([posts,doctopic_df],axis=1)
topic = "Bitcoin and Blockchain"
posts_topics.sort_values( topic,ascending=False)[['poster','title',"body_text",topic]].head(20)
Poster Profiles¶
Here I use the title and topics to predict if a poster will upvote or share something.
That creates a profile of topics and title words a poster likely finds interesting.
Here are some examples:
# Remake the tfidf word matrix with a threshold of 10 instead of 20 counts.
vec_user_profiles = TfidfVectorizer(ngram_range=(1,1),min_df=10,stop_words='english')
X_words = vec_user_profiles.fit_transform(posts.title)
def get_user_profile(user):
model_topics = LogisticRegression(penalty='l2')
y = users_votes[user]
model_topics.fit(doctopic,y)
vocab_topics = zip(topic_names,model_topics.coef_[0])
df_vocab_topics = pd.DataFrame(vocab_topics)
df_vocab_topics.columns = ['topic','coef']
df_vocab_topics = df_vocab_topics[(df_vocab_topics.coef>0)&
(df_vocab_topics.topic.map(lambda x: type(x))!=int)]
model_words = LogisticRegression(penalty='l2')
y = users_votes[user]
model_words.fit(X_words,y)
vocab = zip(vec_user_profiles.get_feature_names(),model_words.coef_[0])
df_vocab = pd.DataFrame(vocab)
df_vocab.columns = ['word','coef']
df_vocab = df_vocab[df_vocab.coef>0]
print user
print
print "Favorite Topics: " +\
", ".join(df_vocab_topics.sort_values('coef',ascending=False).head(10)['topic'])
print
print "Favorite Words: " +\
", ".join(df_vocab.sort_values('coef',ascending=False).head(25)['word'])
return None
get_user_profile('nickgrossman')
get_user_profile('albertwenger')
get_user_profile('BenedictEvans')
get_user_profile('fredwilson')
get_user_profile('aweissman')
get_user_profile('jmonegro')
print
print "The words worked much better than the topics for Joel"
get_user_profile('pointsnfigures')
get_user_profile('kidmercury')